Tableau Prepはデータを分析に適した形に加工するツールで、その処理過程を記録して共有したり再利用したりすることができます。
本ページでは、Tableau PrepのフローにPythonによる処理プロセスを追加する方法を紹介します。
Tableau Prepの標準の機能では扱いにくい処理が必要になった場合には、Pythonスクリプトの導入を検討するのもひとつの手です。
以下ではPythonスクリプトの作成方法と実際にそれらをTableau Prep Builederで実行する方法について解説します。
Pythonスクリプトの作成
Pythonのスクリプトには基本的に、
- 入力データを受け取り処理する関数
- 出力データの形式を定義する関数
の2種類の関数を記述します。
書き方のサンプルを以下に示します。
def functionA(inputdf): # (1)入力データを受け取り処理する関数
# ここに処理を書きます。
return outputdf
def get_output_schema(): # (2)出力データの形式を定義する関数
return pd.DataFrame({
# ここに定義を書きます
})まず最初に入力データを受け取り処理する関数を定義します。
関数の引数(inputdf)として入力データを受け取ります。入力データはPythonのライブラリpandasのDataFrame型オブジェクトとして渡されます。
処理を記述したら、最後にreturn文で出力データ(outputdf)を返します。出力データも入力データと同様にDataFrame型オブジェクトになります。
次に出力データの形式を定義する関数を定義します。
関数名は「get_output_schema」に設定し、関数の中に出力データのフィールドと型をすべて記述します。
データの型には以下のような種類があります。
| 定義式 | データ型 |
|---|---|
| prep_string() | UTF-8の文字列 |
| prep_decimal() | Double値 |
| prep_int() | 整数 |
| prep_bool() | ブール値 |
| prep_date() | 日付「yyyy-MM-dd」 |
| prep_datetime() | 日付と時刻「yyyy-MM-dd HH:mm:ss」 |
処理の実行
Pythonスクリプトを作成した後、Tableau Prep Builder上で処理を実行するまでにはいくつかの準備が必要になります。実際に以下の手順で進めます。
- 手順1TabPyサーバの起動
- 手順2TabPyサーバへの接続設定
- 手順3フローへの追加と処理の実行
手順1. Tabpyサーバの起動
Tabpyサーバをコマンドラインで起動します。
Tabpyサーバがインストールされたディレクトリに移動してシェルスクリプトを実行します。
$ cd /opt/anaconda3/pkgs/tabpy-server-0.2-py37_1/lib/python3.7/site-packages/tabpy_server/
$ ./startup.sh
Found existing state.ini
Initializing TabPy...
Done initializing TabPy.
Web service listening on port 9004ポート番号9004でサービスが開始されました。
Tabpyサーバはあらかじめインスールされている必要があります。以下ではMacにAnaconda環境でTabpyサーバをインストールする方法を紹介しています。

手順2. TabPyサーバへの接続設定
メニューの「ヘルプ」をクリックして、リストから「設定及びパフォーマンス」-「分析の拡張機能接続の管理」を選択します。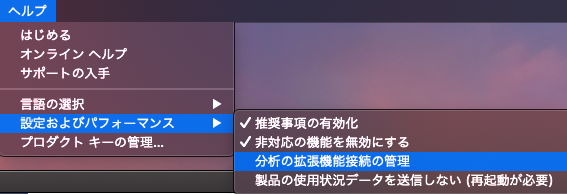
以下のような接続設定画面にて、「Tableau Python (TabPy) Server」を選択して、サーバーとポートを指定します。「9004」はTabPyの標準のポート番号です。必要に応じてユーザ名とパスワードも入力して、最後に「サインイン」をクリックします。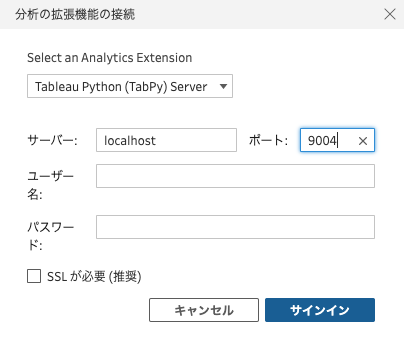
手順3. フローへの追加と処理の実行
準備が整ったのでいよいよPrepのフローにPythonスクリプトの処理を追加して実際に動かしてみます。いくつかの例題を通じて具体的に紹介します。
重複する行を削除するPythonスクリプトを追加してみましょう。
サンプルデータとして以下のファイル(sample1.csv)を利用します。
orderdate,value
2021-05-01,1
2021-05-02,2
2021-05-03,3
2021-05-03,3
2021-05-04,4
2021-05-05,5
2021-05-05,5
2021-05-05,52つのカラム「orderdate」「value」から成る8件のデータで、いくつかの行が重複していることが分かります。
本ファイルがTableau Prep Builderで読み込まれた場合に、重複する行を削除したい場合を考えてみます。
以下のようなPythonスクリプトを作成します。
def DropLine(df):
dropdf = df[~df.duplicated(keep='last')] # 最後の行を除いて重複行を削除
return dropdf
def get_output_schema():
return pd.DataFrame({
'orderdate' : prep_date(),
'value' : prep_int()
})中身を見てみます。
入力データを受け取り処理する関数DropLineと出力データの形式を定義する関数get_output_schemaが記述されています。
DropLine関数はサンプルデータを入力情報(df)として、重複行を削除して結果(dropdf)を返しています。
get_output_schemaでは、2つのフィールドをそれぞれ日付型とINT型で返すことを定義しています。
スクリプトができたらファイル名を「dropduplicates.py」として保存します。
では実際に動かしてみます。
Tableau Prep Builderを起動してファイル「sample1.csv」を読み込みます。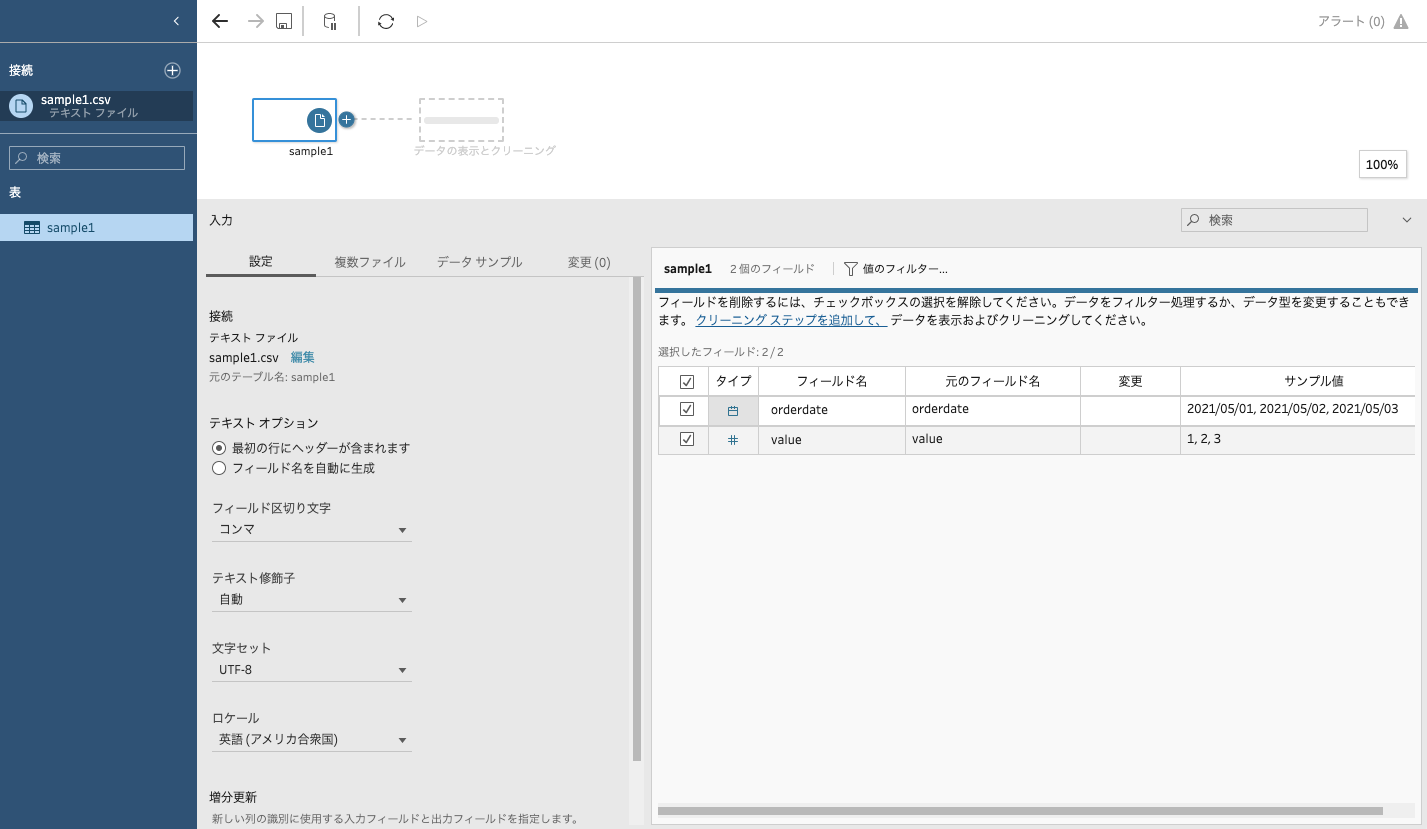
読み込んだファイルのアイコン右にある「+」印をクリックして「スクリプト」を選択します。
スクリプトのプロファイルペインが開きます。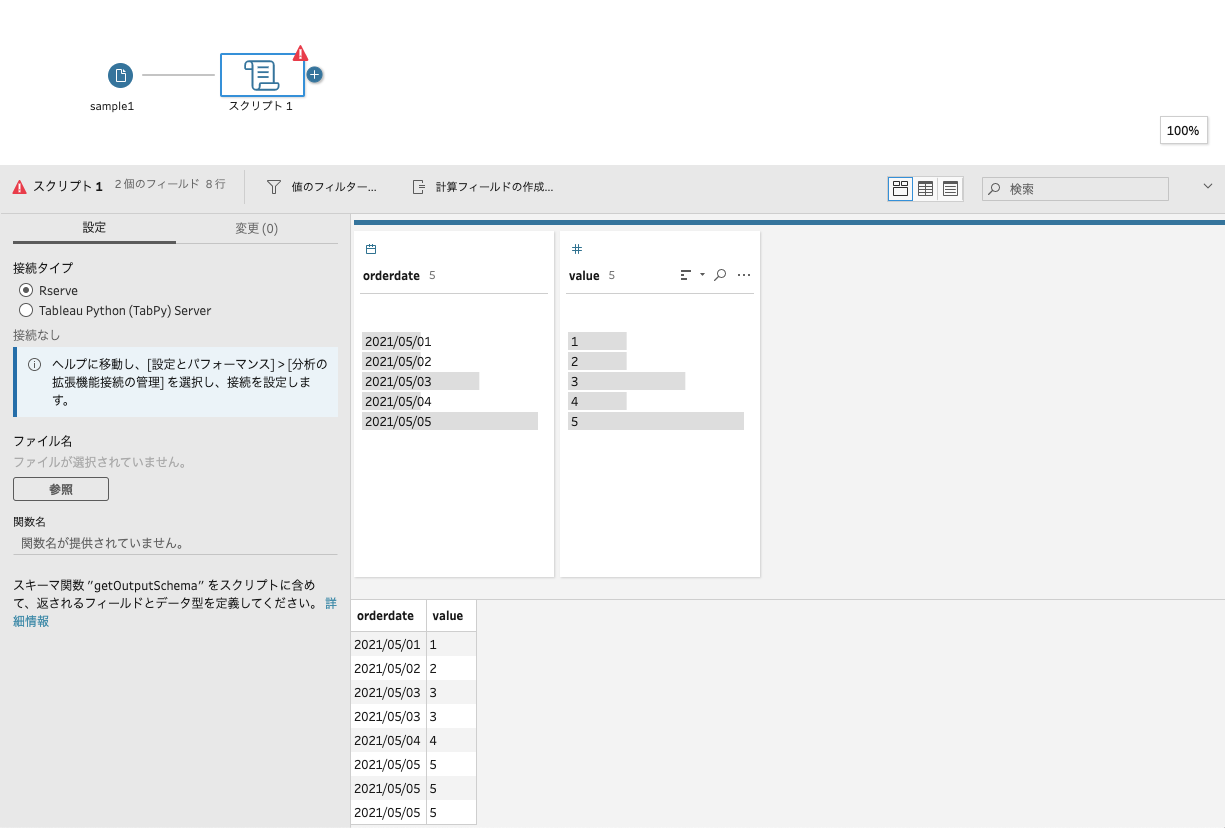
接続タイプの「Tableau Python(TabPy) Server」にチェック入れます。
参照ボタンをクリックして、作成したPythonスクリプトのファイル「dropduplicates.py」を選択します。
さらに関数名の欄には、入力データを受け取り処理する関数「DropLine」と入力します。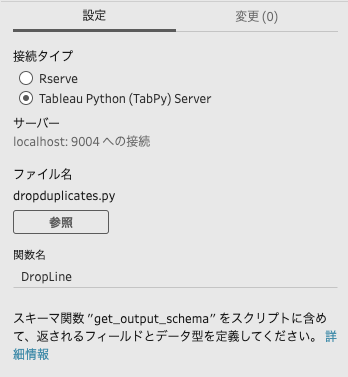
問題がなければ処理が実行されて、プロファイルペインに結果が表示されます。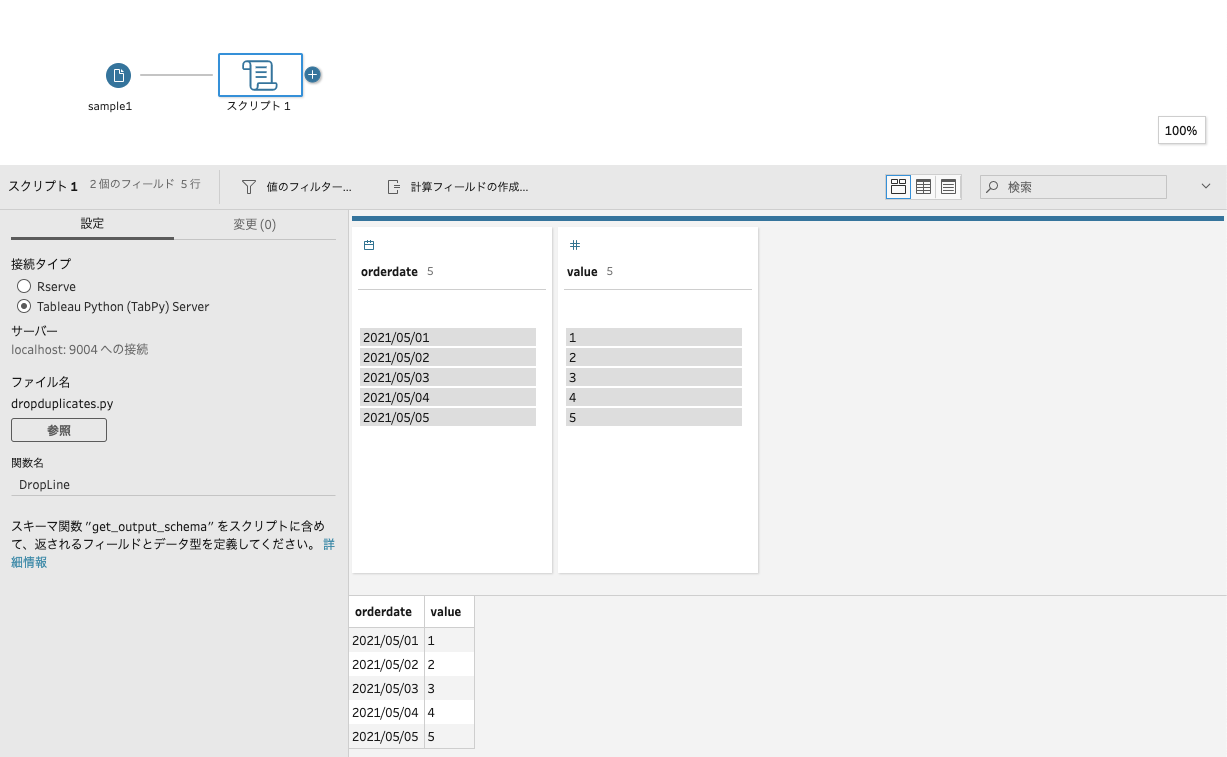
ちゃんと重複行が削除されていることが確認できます。
注文データと商品コード対応表を読み込み、注文データの商品コードを旧データから新データに置換するPythonスクリプトを追加してみましょう。
サンプルデータとして以下2つのファイル、注文データ(sample_order.csv)と商品コード対応表データ(sample_itemcode.csv)を利用します。
▼注文データ(sample_order.csv)
orderdate,name,value,item_code
2021-05-01,A,1,ss-947
2021-05-02,B,2,ww-283
2021-05-03,C,3,tt-297
2021-05-03,C,3,tt-297
2021-05-04,D,4,kk-837
2021-05-05,E,5,hh-864
2021-05-05,E,5,hh-864
2021-05-05,E,5,hh-864▼商品コード対応表(sample_itemcode.csv)
itemcode_old,itemcode_new
ss-947,ss-947
ww-283,ww-299
tt-297,tt-297
hh-864,hh-902やりたいことは、注文データの商品コード(item_code)に対して、商品コード対応表を参照して古い商品コード(itemcode_old)を新しい商品コード(itemcode_new)に置き換える処理です。
以下のようなPythonスクリプトを作成します。
def ReplaceItemcode(order_df):
# 商品コード対応表を読み込み
icd_df = pd.read_csv('/Users/test/workspace/sample_itemcode.csv')
# 新旧商品コードデータをlistに格納
icd_old = icd_df['itemcode_old'].to_list()
icd_new = icd_df['itemcode_new'].to_list()
# 辞書を作成して置換
icd_dict = {}
for o, n in zip(icd_old, icd_new):
icd_dict[o] = n
rule_dict = {'item_code': icd_dict}
repdf = order_df.replace(rule_dict)
return repdf
def get_output_schema():
return pd.DataFrame({
'orderdate' : prep_date(),
'name' : prep_string(),
'value' : prep_int(),
'item_code' : prep_string()
})
中身を見てみます。
入力データを受け取り処理する関数ReplaceItemcodeと出力データの形式を定義する関数get_output_schemaが記述されています。
ReplaceItemcode関数は注文データを入力情報(order_df)として、商品コード対応表をファイルから読み込み、新旧対応コードを辞書に格納して置換、結果(repdf)を返しています。
get_output_schemaでは、4つのフィールドを日付型やINT型、文字列型で返すことを定義しています。
スクリプトができたらファイル名を「replace_itemcode.py」として保存します。
では実際に動かしてみます。
Tableau Prep Builderを起動してファイル「sample_order.csv」を読み込みます。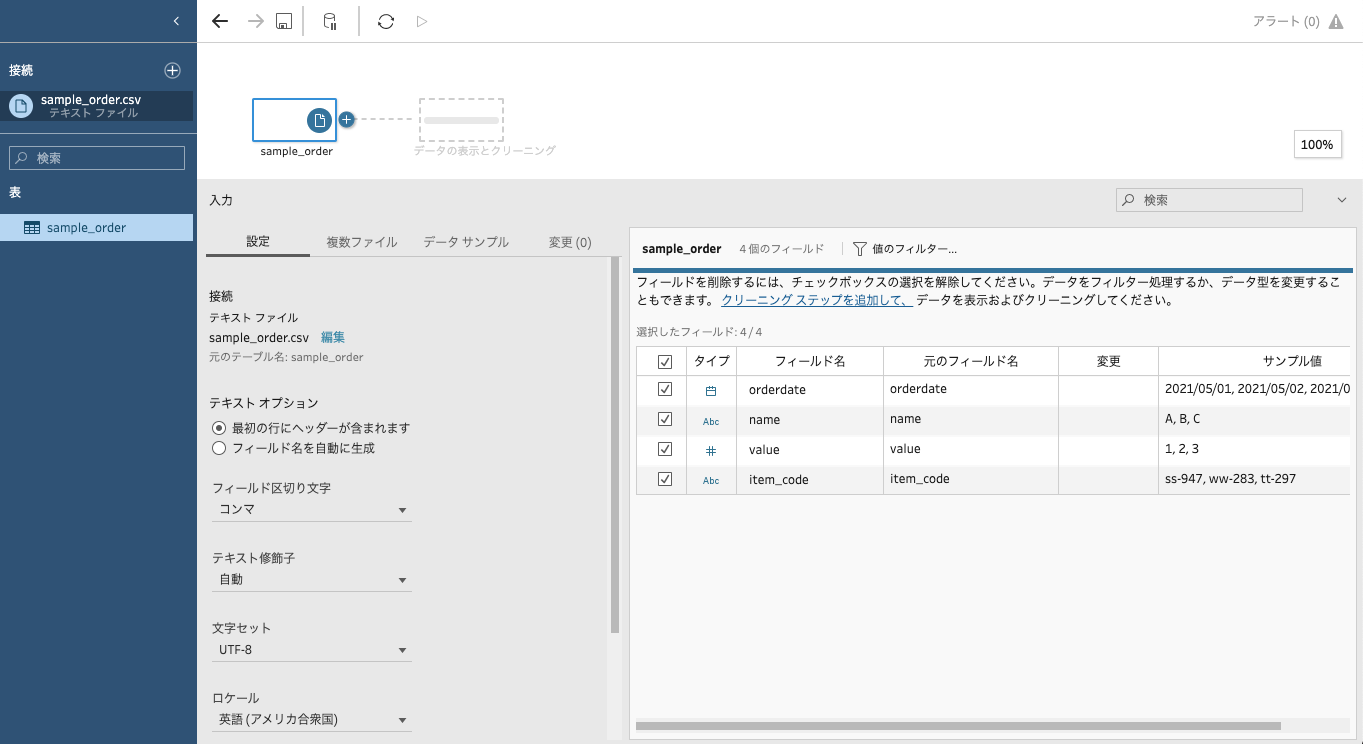
読み込んだファイルのアイコン右にある「+」印をクリックして「スクリプト」を選択します。
スクリプトのプロファイルペインが開きます。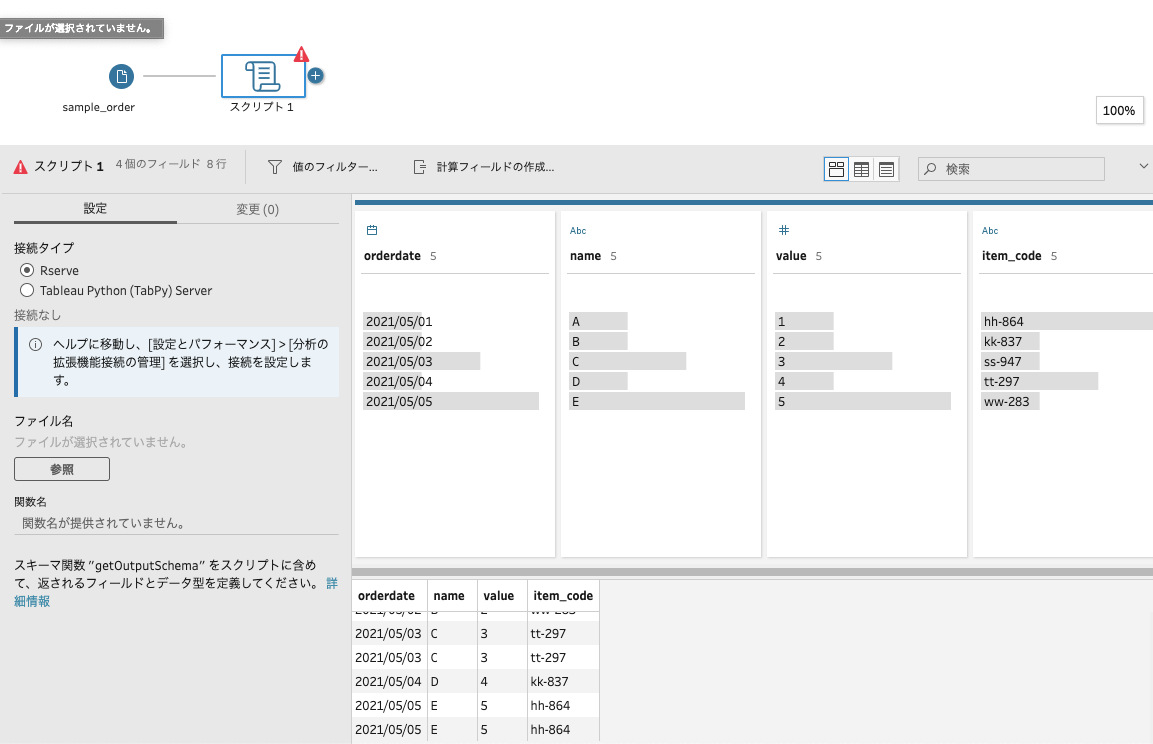
接続タイプの「Tableau Python(TabPy) Server」にチェック入れます。
参照ボタンをクリックして、作成したPythonスクリプトのファイル「replace_itemcode.py」を選択します。
さらに関数名の欄には、入力データを受け取り処理する関数「ReplaceItemcode」と入力します。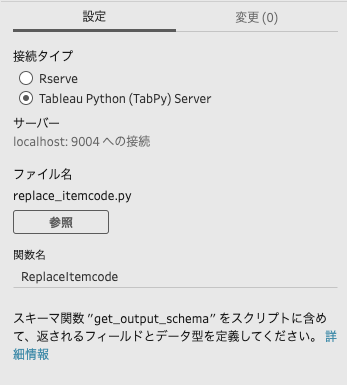
問題がなければ処理が実行されて、プロファイルペインに結果が表示されます。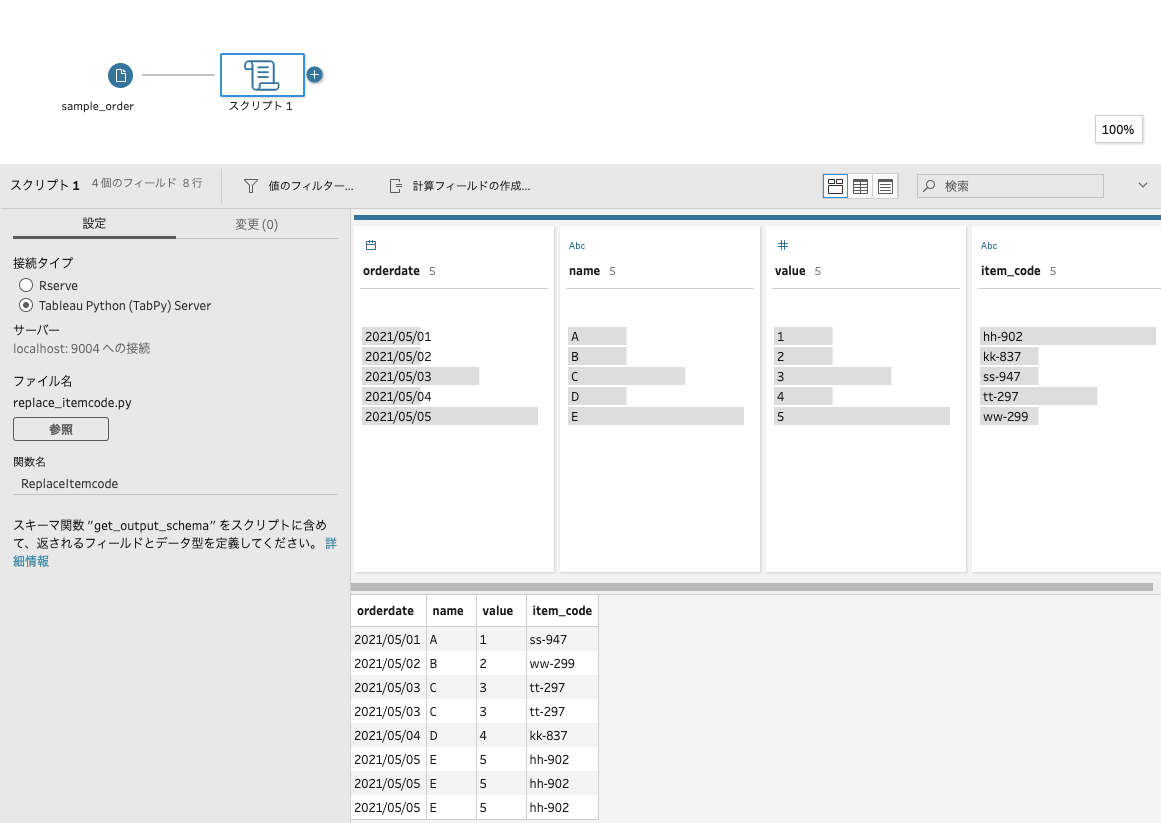
正しく商品コードが置換されていることが確認できます。
本ページでは、Tableau Prep BuilderのフローにPythonによる処理プロセスを追加する方法を紹介しました。