Google Cloudにデータパイプラインを作成することによって、様々な用途に応じたデータを提供する環境を構築することができます。
本ページでは、データパイプラインとは何か、なぜ必要なのか、ETLとの違い、関連するGoogle Cloudのプロダクトを紹介します。
データパイプラインとは?
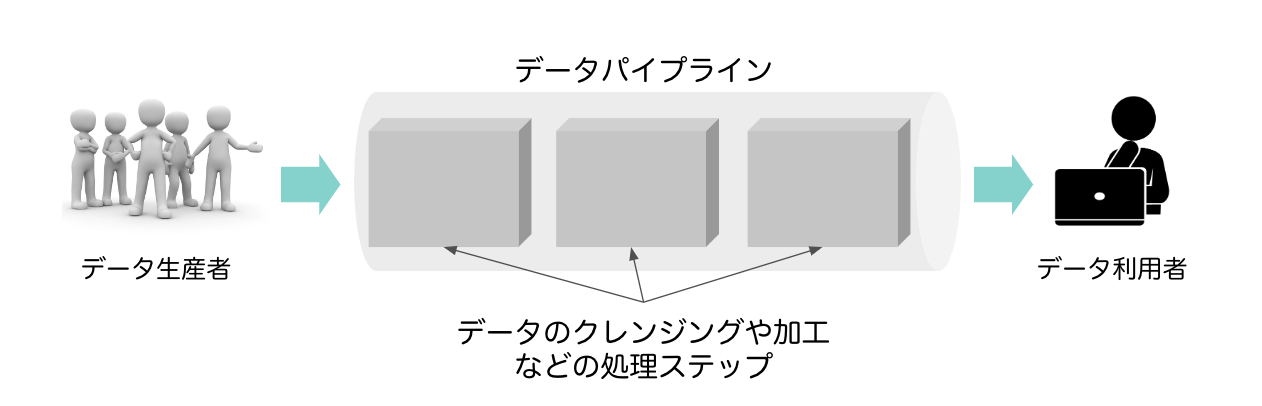
データを産み出す人とデータを利用する人をつなぐ経路のことをデータパイプラインと呼びます。
ECサイトを例に考えてみましょう。
この場合、データを産み出す人はサイトのユーザ、データを利用する人はサイト運営企業の人になります。
産み出されるデータは、ECサイト内でのクリック履歴データやユーザが登録する個人情報だったりします。
一方でデータ利用者は、会社の経営層であったり、マーケティング担当者であったりします。会社の経営層であれば月間の売上レポートを閲覧したり、マーケティング担当者であればセールス施策の効果を検証したり、次の四半期の売上予測をしたりします。
このように、発生元で産み出されるデータと利用者側で使いたいデータには乖離があり、生産されるデータを利用しやすい形に変換したり、他の様々なデータと突合させる必要があります。そのようなデータのクレンジングや加工のステップ、その際に利用する様々なデータソース等すべてがデータパイプラインに相当します。
個人や企業で様々なデータが収集して活用する機会が増えてきたため、データを利用者の目的や用途に応じて準備するプロセスをできるだけ効率よく作成する必要が生じたからです。
例えばサービスの分析用のデータ、機械学習を適用するためのデータ、あるいはビジネスレポート作成用データというように、利用者のニーズに応じて様々なデータを準備する必要があります。
そのようなデータを作成する過程において、多くの人が実行する類似処理をデータパイプライン上で共通化し、データを一元管理することによって、リソースの無駄使いを減らすことができます。
また、毎日実行する処理に関しても、データパイプライン上で自動化しておけばヒューマンエラーを軽減させることができます。
データパイプラインはデータ生産者と利用者を結ぶすべての工程の総称で、ETLはデータパイプラインの一部の工程を指します。
例えば、ECサイトを例に考えてみましょう。
各店舗の売り上げデータがトランザクション処理で会社の基幹システムに蓄積されていて、毎日深夜に分析用のデータベースにロードされているとすると、この処理はETL処理と呼ぶことができます。
一方で、ECサイト上に在庫状況を表示する場合には、リアルタイムで購買のデータと在庫のデータを商品ごとに比較する処理が必要になります。この場合には、ETL処理に加えて、毎秒や毎分の頻度でリアルタイムにデータを処理するストリーミング処理が必要になります。そのような様々なデータを収集して加工する際の一連の処理工程や関連するすべてのデータソースをすべて含めてデータパイプラインと呼ぶことができます。
図にすると以下のようになります。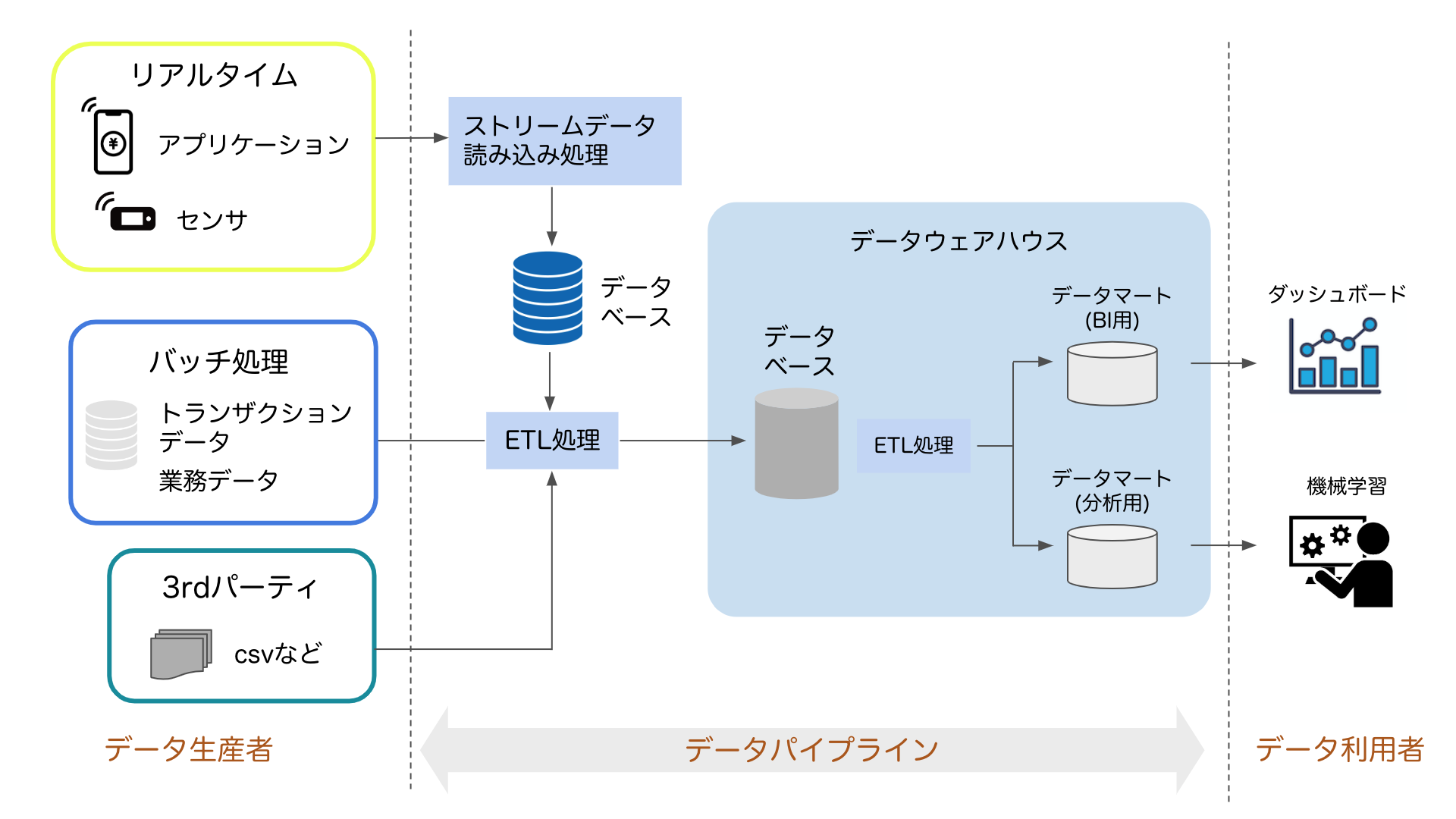
ETL処理は業務システムのデータやストリームデータを抽出するデータパイプラインの初期の段階で実行したり、データウェアハウス内での様々な用途向けのデータマート作成時にも実行したりするなど、データパイプラインの様々な箇所で利用されます。
Google Cloudの関連プロダクト
ではデータパイプラインは実際にどのように作成していったらよいのでしょうか?
ここではGoogle Cloud上にデータパイプラインを作成する場合に、よくあるデザインのパターンの一例と各工程で関連するプロダクトを紹介したいと思います。
図に表すと以下のようになります。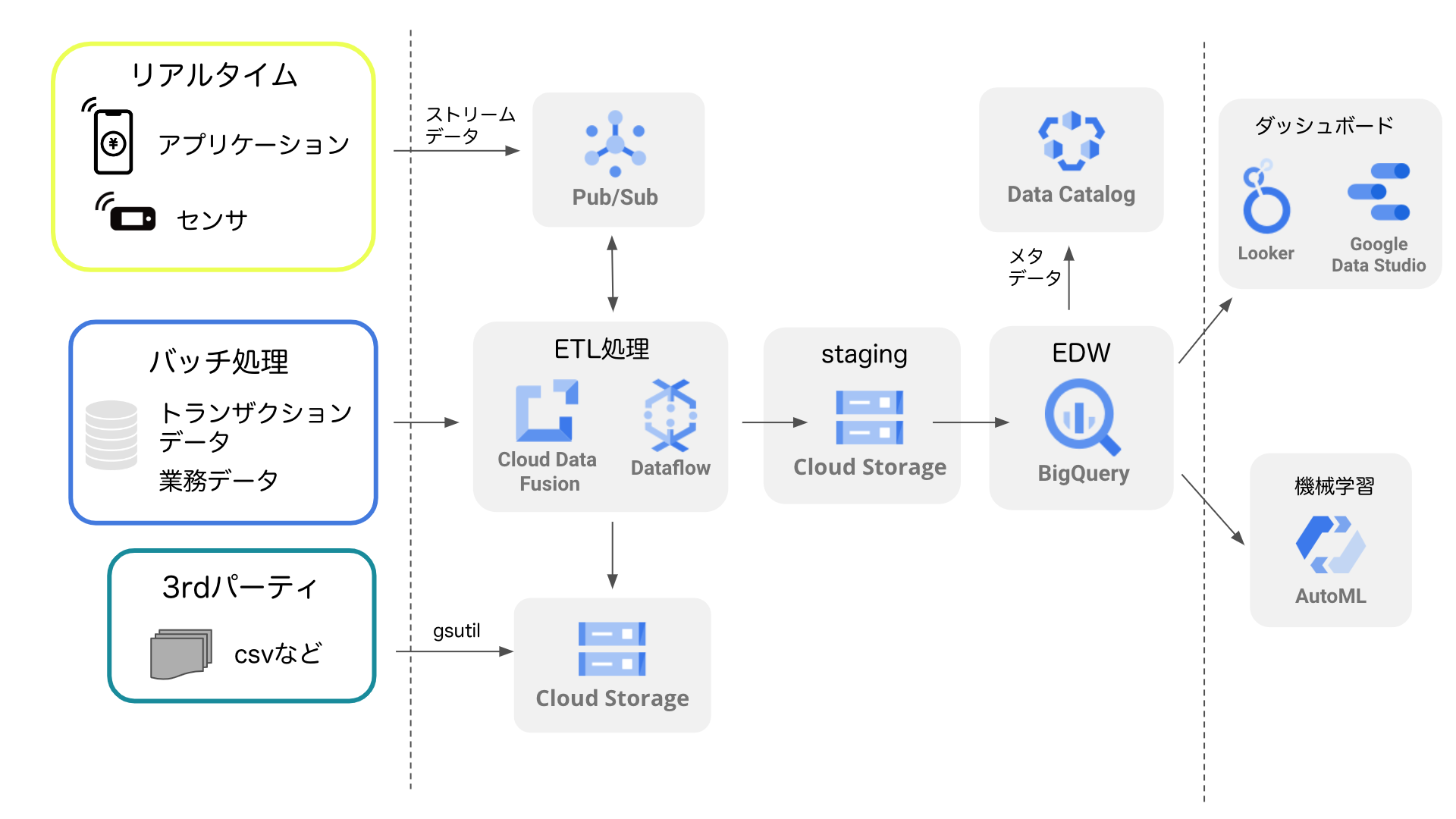
左上のアプリやセンサからのリアルタイムのデータは、Pub/Subで発生イベントが検知されETL処理に渡されます。左真ん中の基幹システムのデータは、1日1回などのバッチ処理で定期的にETL処理に渡されます。左下の3rdパーティのデータは定期的にCloud Storageに置かれて、ETL処理時に利用されます。
上記のような様々なデータを入力として、ETL処理ではデータのクレンジング・加工などを実行します。Google CloudのETL処理用のプロダクトはいくつも種類がありますが、ここではDataflowとCloud Data Fusionを代表例として挙げます。Dataflowはサーバなしにコーディングで自由度高くETL処理を実装することができます。一方のCloud Data Fusionはコードを書かずにGUIで処理フローを定義できるというメリットがあります。
ETL処理で加工されたデータは、ノイズが除去されたもののローデータの形式のため、本番環境前のステージング環境に一旦置かれることが多いです。ステージング環境にはCloud Storageを利用したり、各種データベースのテーブルを利用したりします。そして、ステージング環境からさらにETL処理を繰り返して、データはEDW(Enterprise Data Warehouse)に置かれます。EDWにはGoogle Cloudの代表的なプロダクトであるBigQueryを導入して、ローデータに近いテーブルから用途に応じたデータマートまで様々なテーブルを作成することができます。
最終的に、用途別に作成されたデータマートを利用してLookerやGoogle Data Studioなどを利用してダッシュボードや分析レポートを作成したり、機械学習を適用したりすることができるようになります。
本ページでは、データパイプラインとは何か、なぜ必要なのか、ETLとの違い、関連するGoogle Cloudのプロダクトを紹介しました。