
BigQueryは多種多様なビッグデータの格納やインポート処理、分析が可能なGoogleのデータウェアハウスサービスです。
本ページでは、Google Cloud Storage(GCS)にあるデータをBigQueryのテーブルにロードする方法を紹介します。
読み込む方法は、基本的にローカルファイルをテーブルにロードする場合と同様に、
- Cloud Console
bqコマンドラインツール- BigQuery API
を利用することができます。
上記3つの方法で実際にCloud Storageのバケットのデータを読み込んで、BigQueryのテーブルを作成してみます。
今回使用するデータは、Cloud Storageのバケットの「eforexcel-sales」フォルダにある「SalesRecords_1000.csv」です。
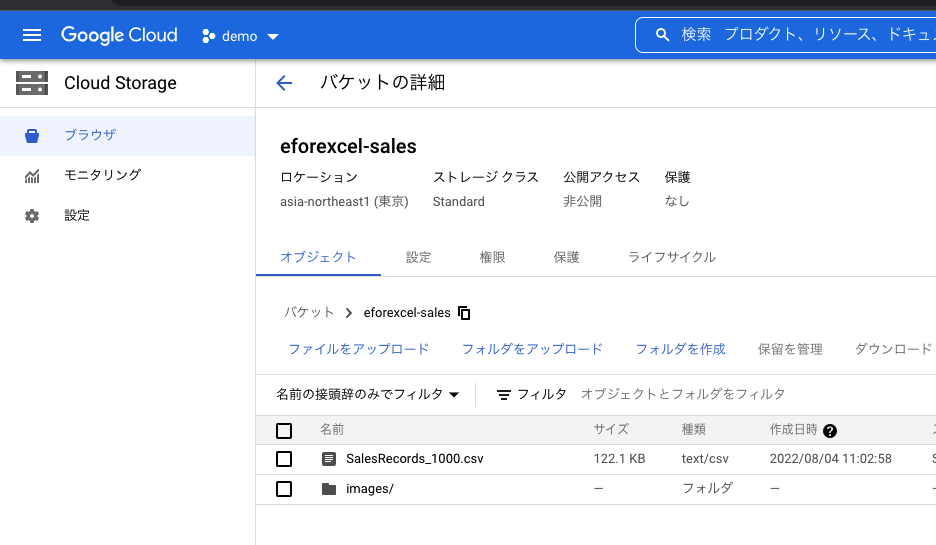
1,000件のレコードから成るヘッダ付きのCSV形式の売上データで、以下のような内容になっています。

Cloud Console
ブラウザでBigQueryにテーブルを作成する方法です。
すべてGCPのWeb UI画面上で設定しながら進めることができます。
実際にCloud Storageのファイルを読み込んでみます。
BigQueryを起動して、データセットを選択、テーブルを作成します。
(データセットが未作成の場合は、新規にデータセットを作成してからテーブルを作成します。)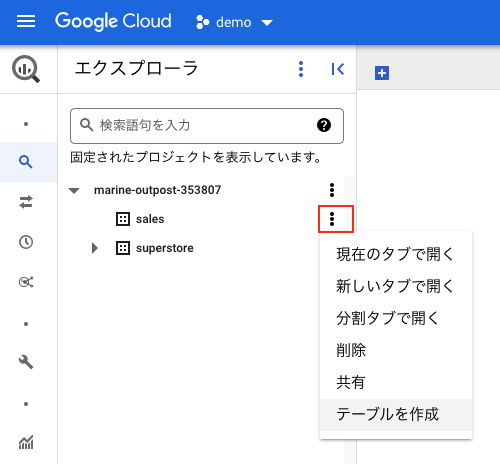
テーブルの作成元は「Google Cloud Storage」、ファイルとファイル形式を指定、テーブル名を入力して、スキーマの「自動検出」にチェックを入れます。自動検出をオンにすると、BigQueryがデータの型を推定して設定してくれます。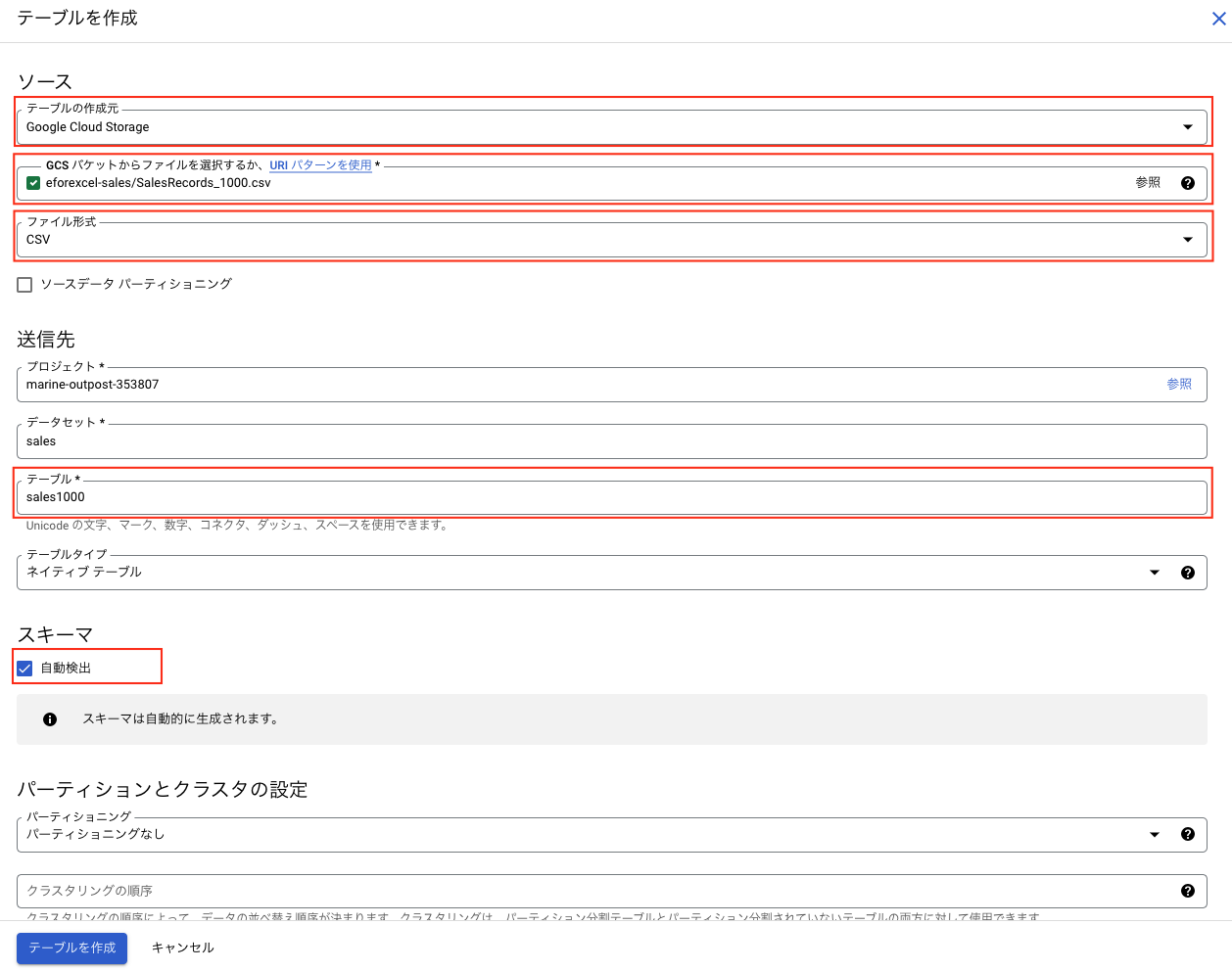
テーブルが作成されました。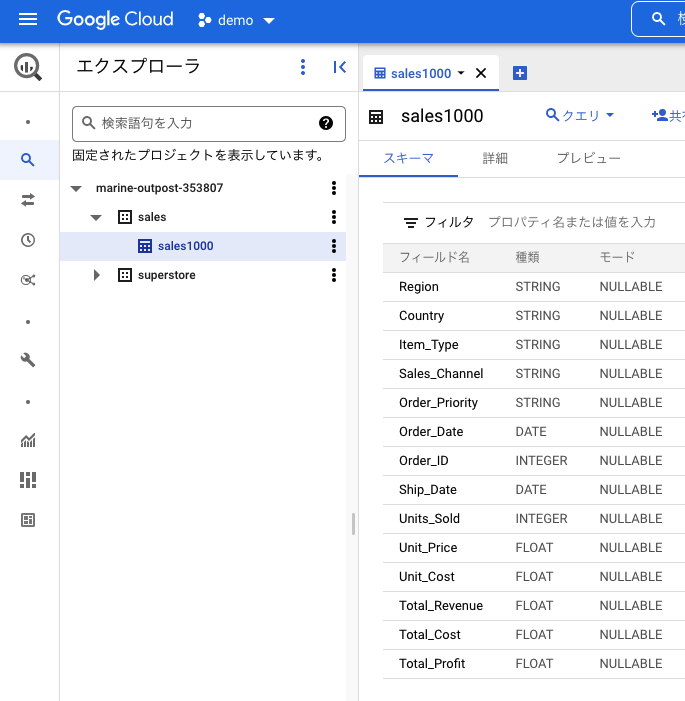
bqコマンドライン
Googleから提供されているBigQueryを操作するコマンドラインツール「bqコマンド」を利用する方法です。
GCPのCloud Shellのターミナルを立ち上げると、インストール不要ですぐに利用できます。
実際にbqコマンドを利用してCloud Storageのファイルを読み込んでみたいと思います。
まず最初に画面右上のアイコンをクリックしてCloud Shellを起動します。
以下のように画面が立ち上がります。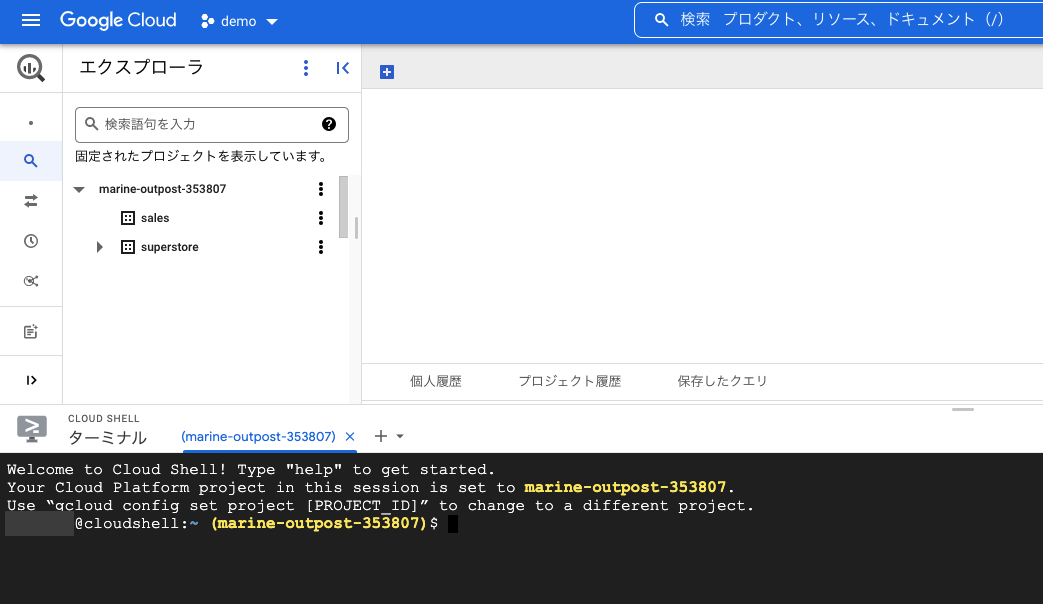
bqコマンドを利用してBigQueryにロードします。
「gs://eforexcel-sales/SalesRecords_1000.csv」からデータセット「sales」の「sales1000」というテーブルにデータを読み込みます。スキーマは自動検出されます。
Cloud StorageのファイルのURIは、オブジェクトの詳細を表示すると記載されています。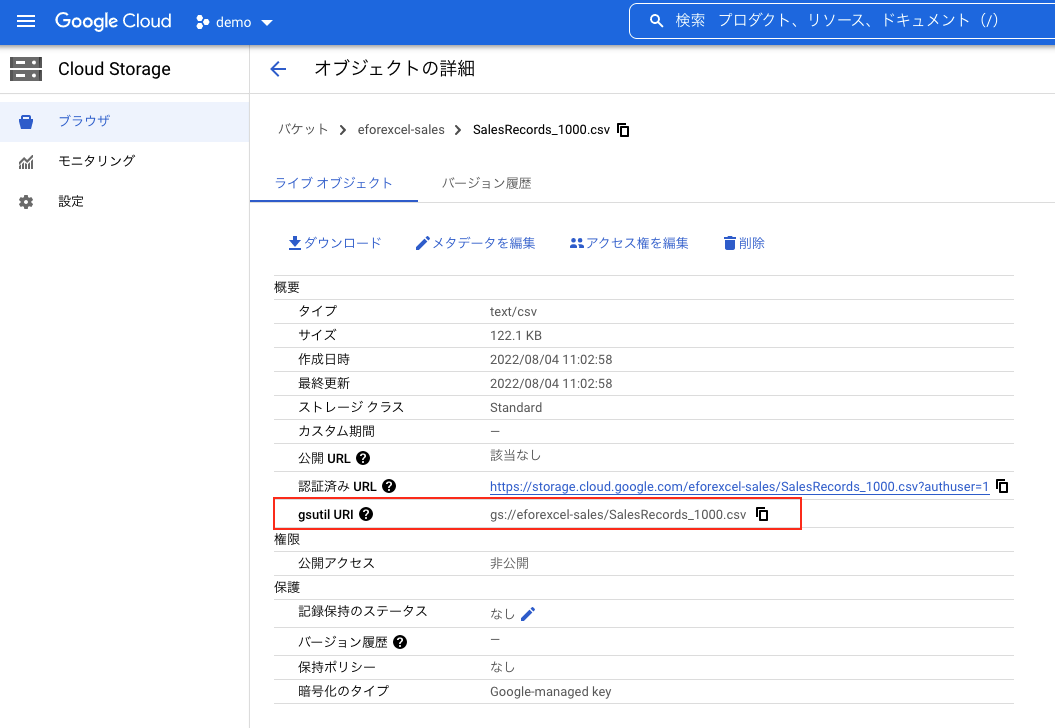
最終的にテーブルが作成されたことを確認できました。
BigQuery API(python)
Googleから提供されているBigQuery APIを利用して、コードからファイルをロードする方法です。
GCPのCloud Shellを利用すれば、APIパッケージがインストール済みなので、エディタでコードを作成してターミナルで実行することができます。
ここではpythonを例に、実際にCloud Storageのファイルを読み込んでみたいと思います。
まず最初に画面右上のアイコンをクリックしてCloud Shellを起動します。
以下のように画面が立ち上がります。
続いて「エディタを開く」をクリックして、エディタを起動します。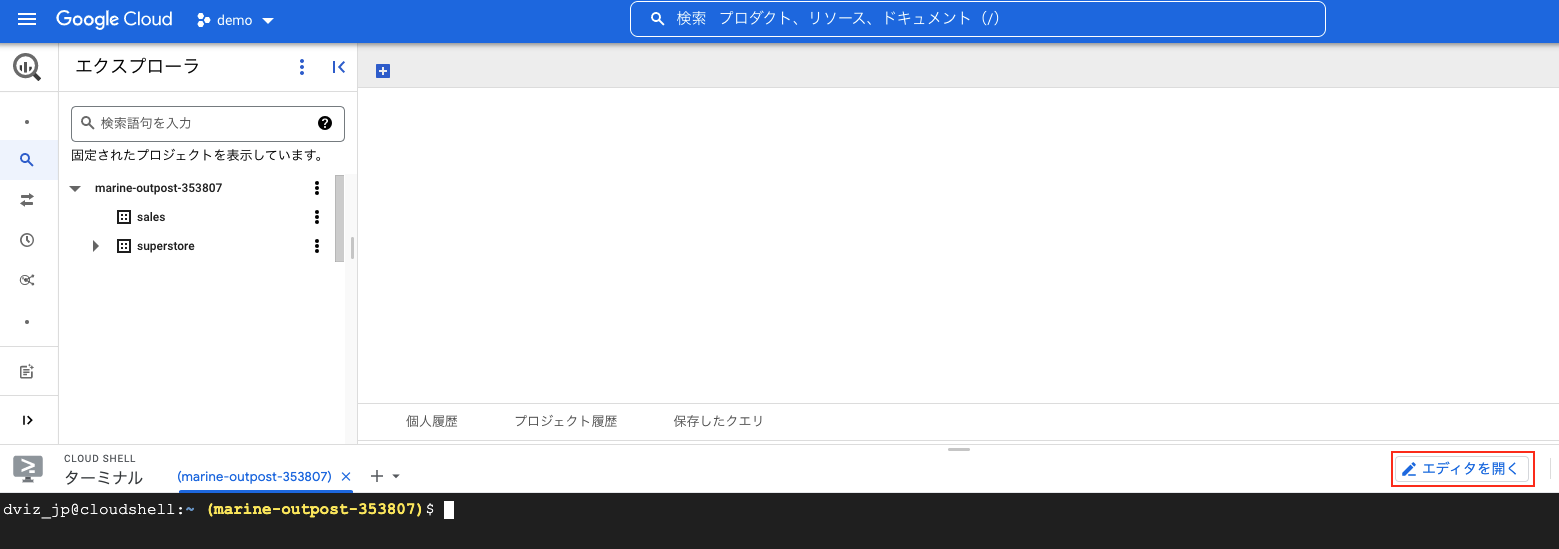
エディタでpythonのコードを作成します。
メニューの「File」をクリックして、リストから「New File」を選択します。
以下のようなpythonのコードを作成します。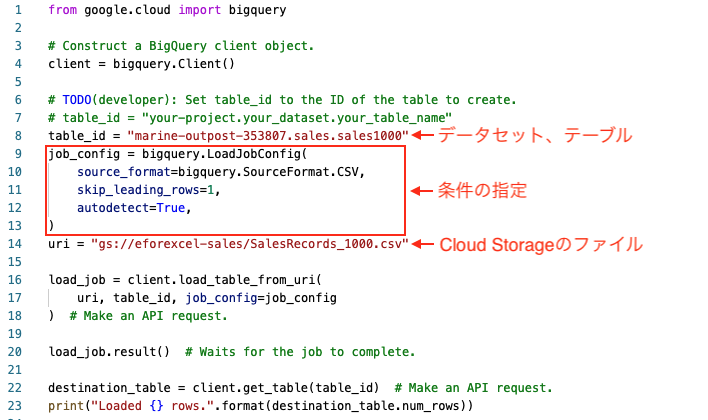
メニューの「File」をクリックして、リストから「Save as」を選択、名前を付けて保存します。
今回は「load_storage2bq.py」で保存しました。
画面右上の「ターミナルを開く」をクリックして、再びターミナルに切り替えます。
pythonのファイルを実行します。![]()
BigQueryを開いて、作成されていることが確認できます。
本ページでは、Google Cloud Storage(GCS)にあるデータをBigQueryのテーブルにロードする方法を紹介しました。

今回は自動検出オプション(–autodetect)やファイル形式オプション(–source_format)を利用していますが、csvデータ読み込みの際に指定可能なオプションは色々あります。
詳細は以下のGoogleのサイトに掲載されています。