
BigQueryは多種多様なビッグデータの格納やインポート処理、分析が可能なGoogleのデータウェアハウスサービスです。
本ページでは、Googleのアカウントがあればすぐに利用できるsandboxを利用して、BigQueryの使い勝手をお試しする方法を紹介します。
sandboxの始め方
BigQueryには「sandbox」と呼ばれるGoogle Cloudの無料枠とは別物の仕組みがあります。
sandboxはGoogle Cloudの無料枠で必要なクレジットカードの登録が必要ありません。その割に多くの機能をブラウザでお試し利用できるので、BigQueryが気になっていて触ってみたい方におすすめです。
sandbox利用の主な制約は、2022年6月現在以下のようになっています。
- ストレージの使用量の上限は10GB/月
- クエリによるデータ処理量の上限は1TB/月
- テーブルの有効期間は60日間
- データ操作言語(DML)は使用できない
いずれの条件も、使い勝手を知る分には気にならないと言えそうです。
なお、条件は変更されるかもしれないので、最新情報はBigQuery サンドボックスについてをご確認ください。
では早速sandboxを開いてみます。
Googleのアカウントを取得したら、sandboxスタートガイドにあるように、ブラウザで以下のURLを入力して
https://console.cloud.google.com/bigqueryBigQuery sandboxにアクセスします。
成功するとsandboxのバナーが表示されたページが開きます。
BigQueryのSQLワークスペースは以下のような表示になっています。
画面左にBigQueryの機能一覧、その右にプロジェクトやデータセット、テーブルの一覧、画面右にはSQLのエディタとクエリ処理の結果や履歴を表示するエリアが表示されます。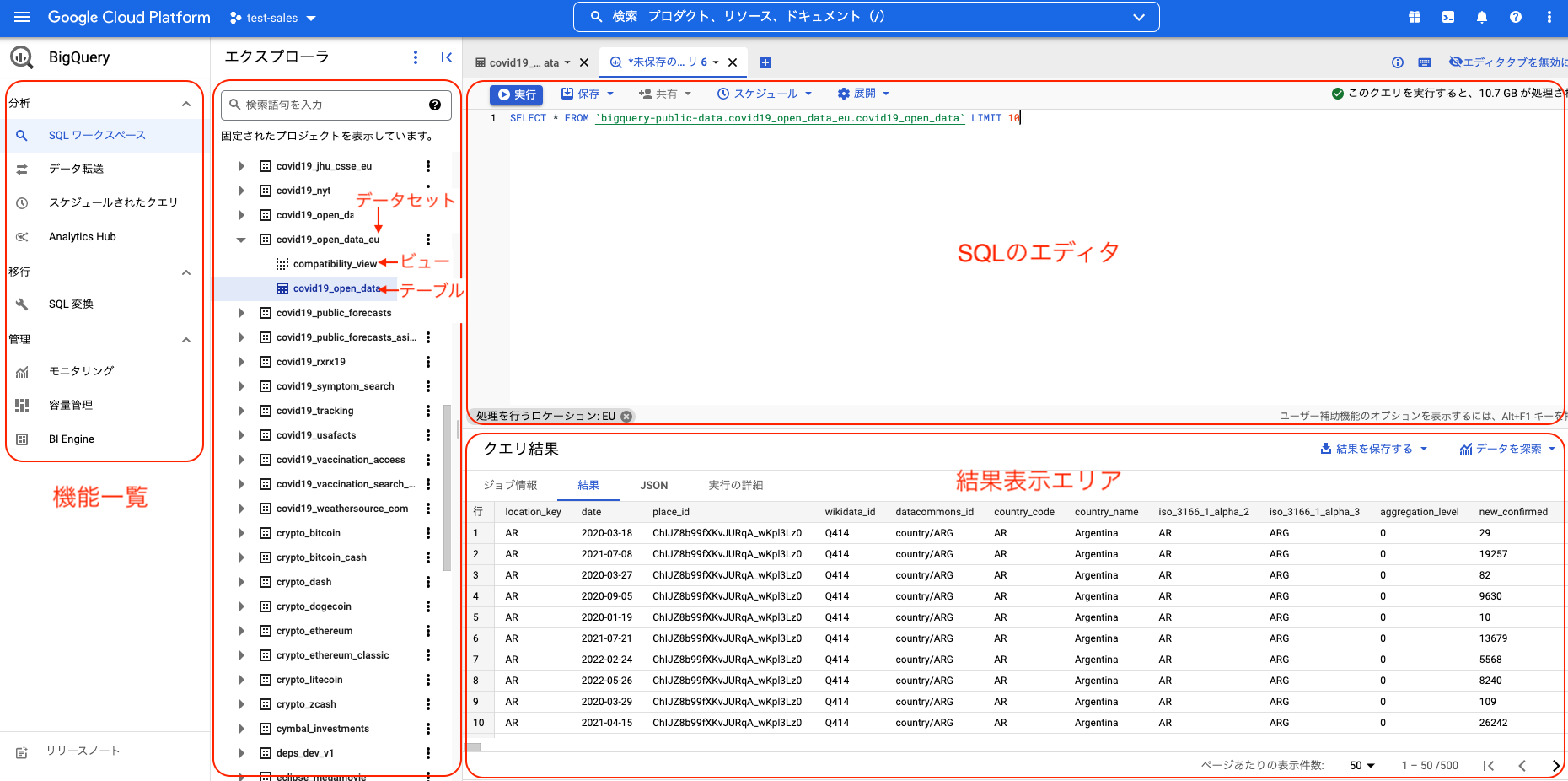
BigQueryでは、ひとつのアカウントで複数のプロジェクトを作成することができます。よくある例としては、開発用と本番用でプロジェクトを分けたりします。
さらにひとつのプロジェクトは複数のテーブルやビューを含むデータセットで構成されています。
例えば、開発用プロジェクトにて、ログデータを蓄積するデータセットとそれらをクレンジングしたデータを保持するデータセット、さらにデータ分析用途で利用するデータセットのように、複数のデータセットを用意したりします。
テーブルの作成
実際にローカルPCにあるファイルをアップロードしてBigQueryのテーブルを作成してみます。
ファイルのデータは以下のようなヘッダ付きのCSV形式で、1,000件のテスト用セールスデータです。(データ提供元: E for Excel)
まずはプロジェクトを作成します。
上段のプロジェクト名をクリックするとプロジェクト選択画面が現れるので、「新しいプロジェクト」をクリックします。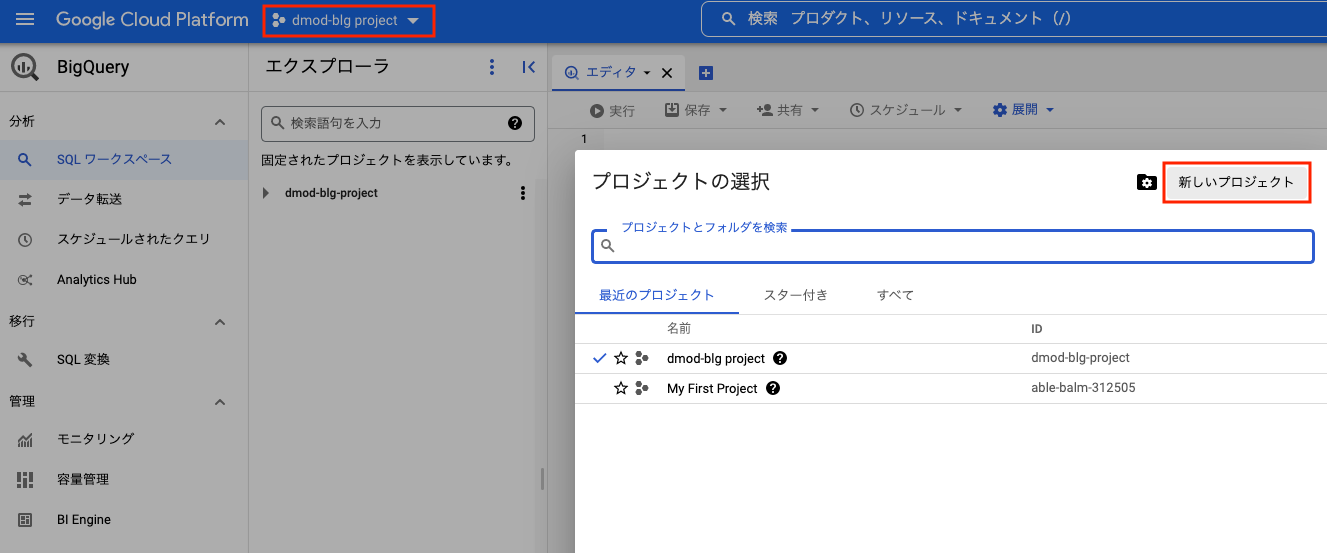
プロジェクト名を入力して「作成」をクリックします。
(実際に作成されるプロジェクト名は「プロジェクト名-ID」になります。)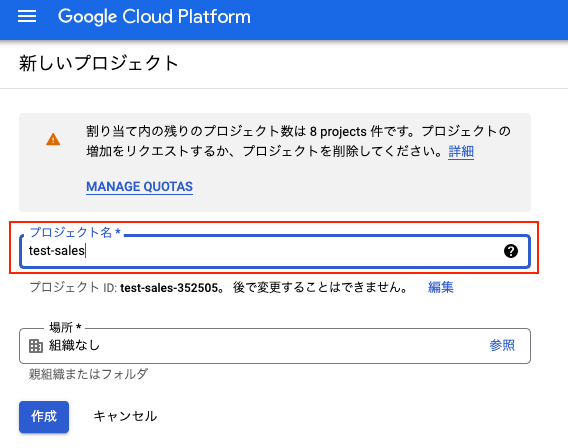
次にデータセットを作成します。
プロジェクトの右端をクリックして「データセットを作成」を選択します。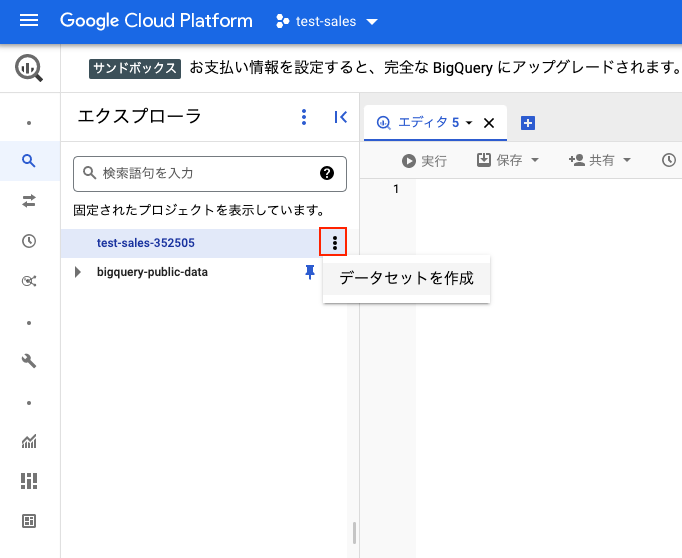
データセットIDを入力して「データセットを作成」をクリックします。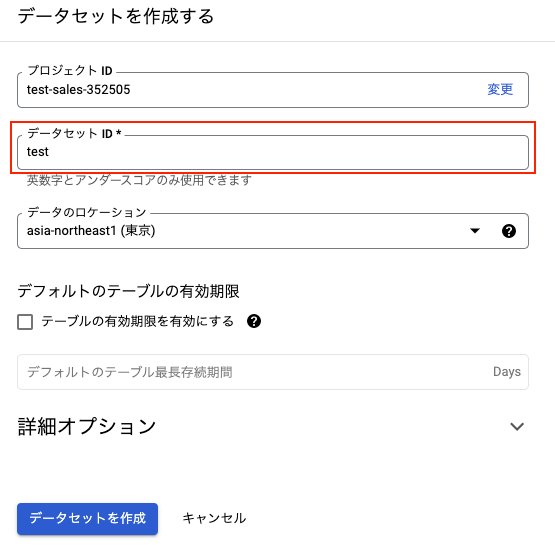
さらにテーブルを作成します。
データセットの右端をクリックして「テーブルを作成」を選択します。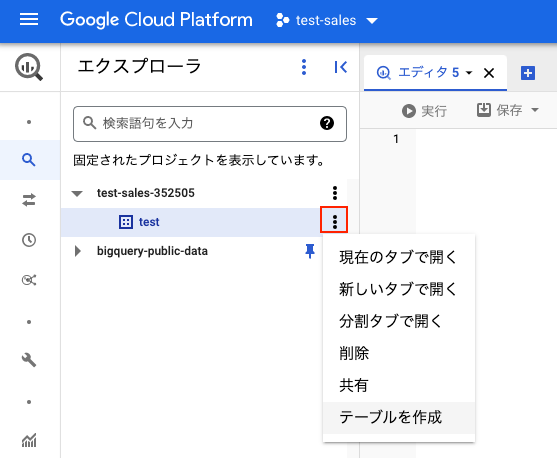
ファイル形式を「csv」に設定、テーブル名を入力して、スキーマの「自動検出」にチェックを入れます。
自動検出をオンにすると、BigQueryがデータの型を推定して設定してくれます。設定後に手動で変更することもできます。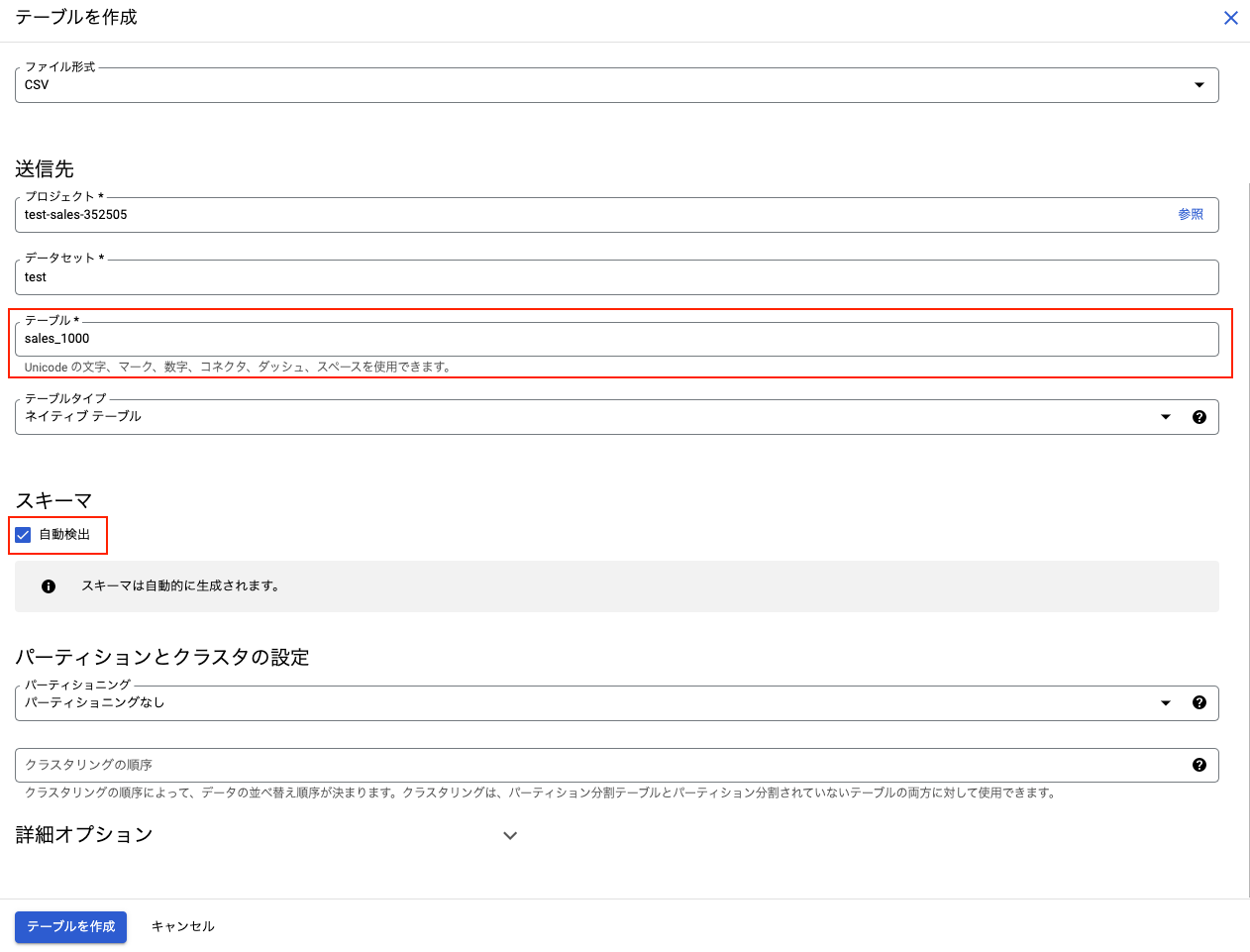
テーブルが作成されました。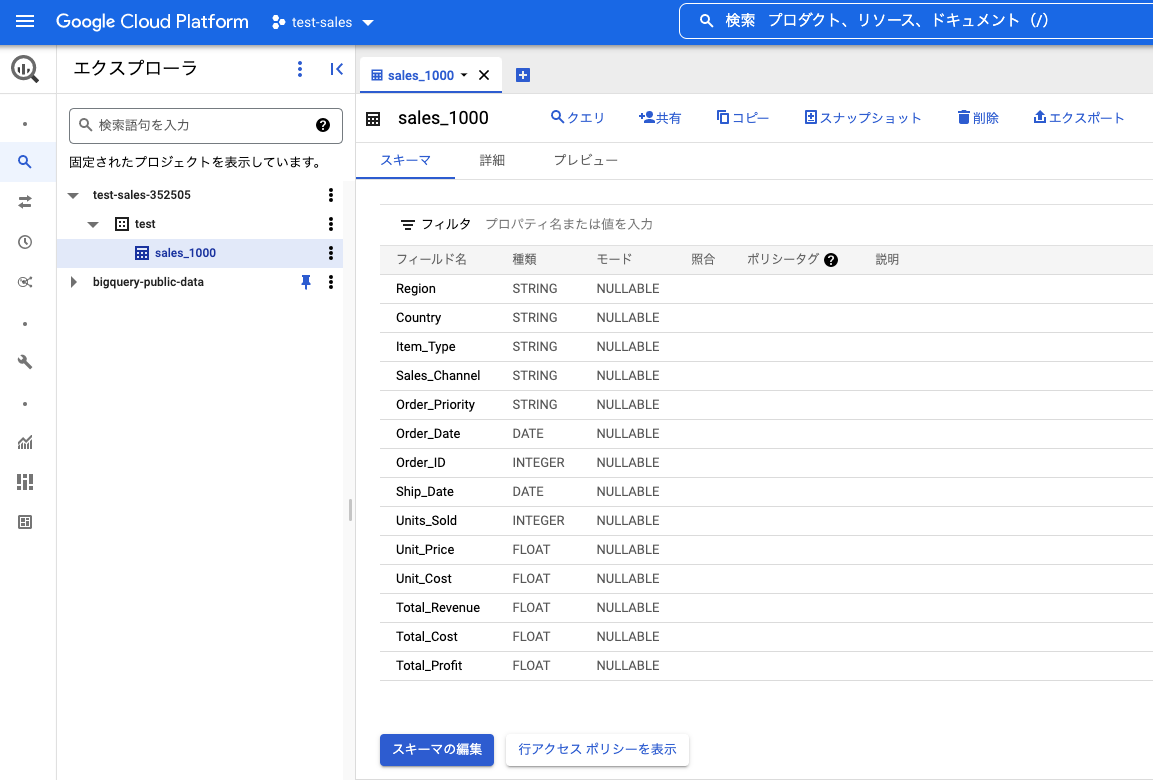
SQLによるデータの処理
今度は作成されたテーブルに対してSQLでデータの抽出・加工をしてみます。
テーブルの右端をクリックして「クエリ」を選択します。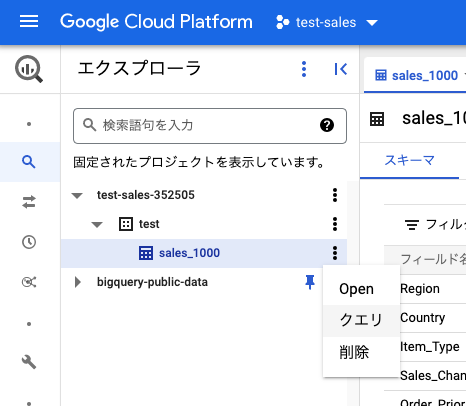
画面上部のSQLのエディタにSELECT文を入力して「実行」をクリックすると、画面下部に処理結果が表示されます。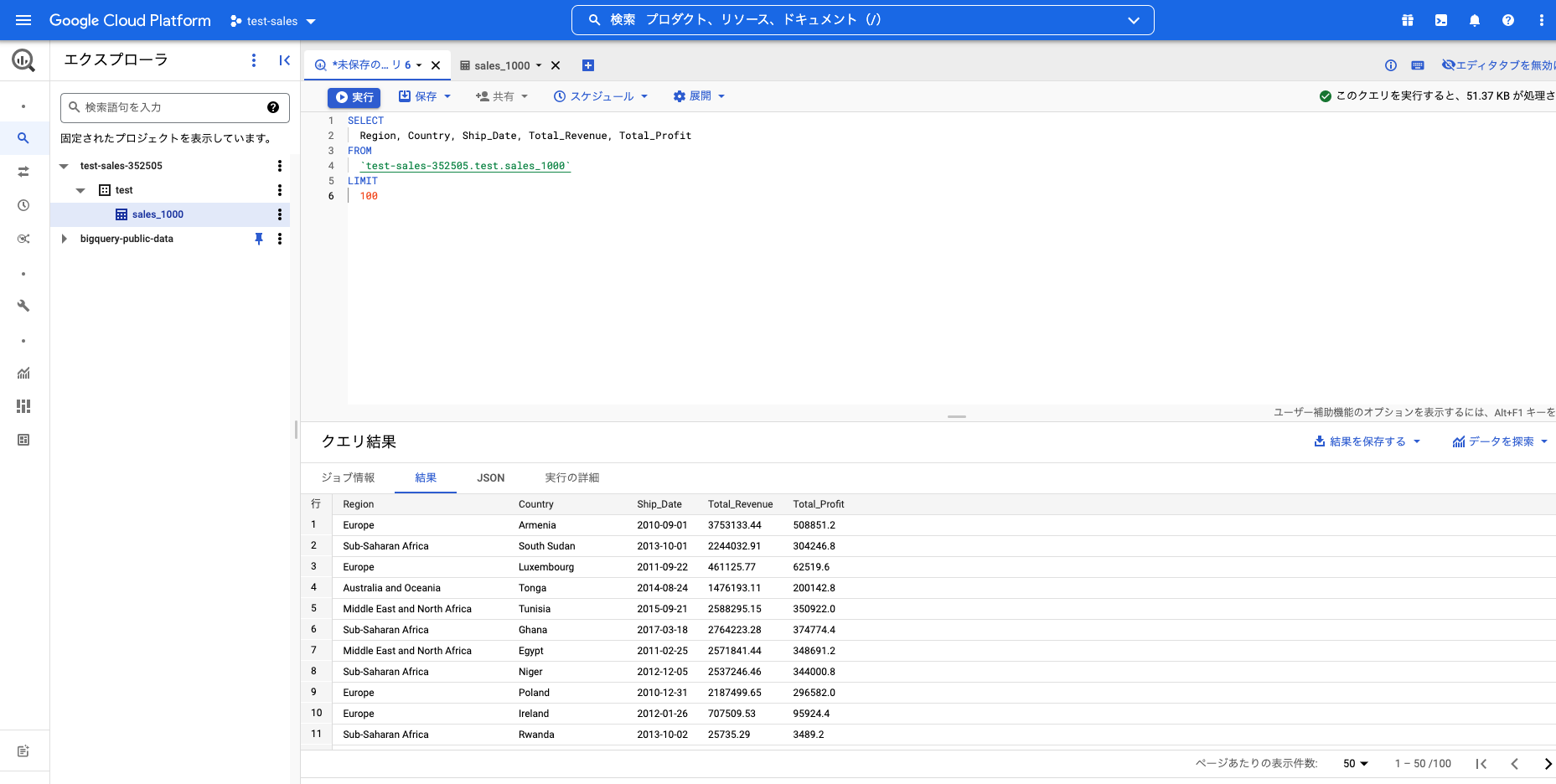
集計関数SUMやGROUP BYも利用できます。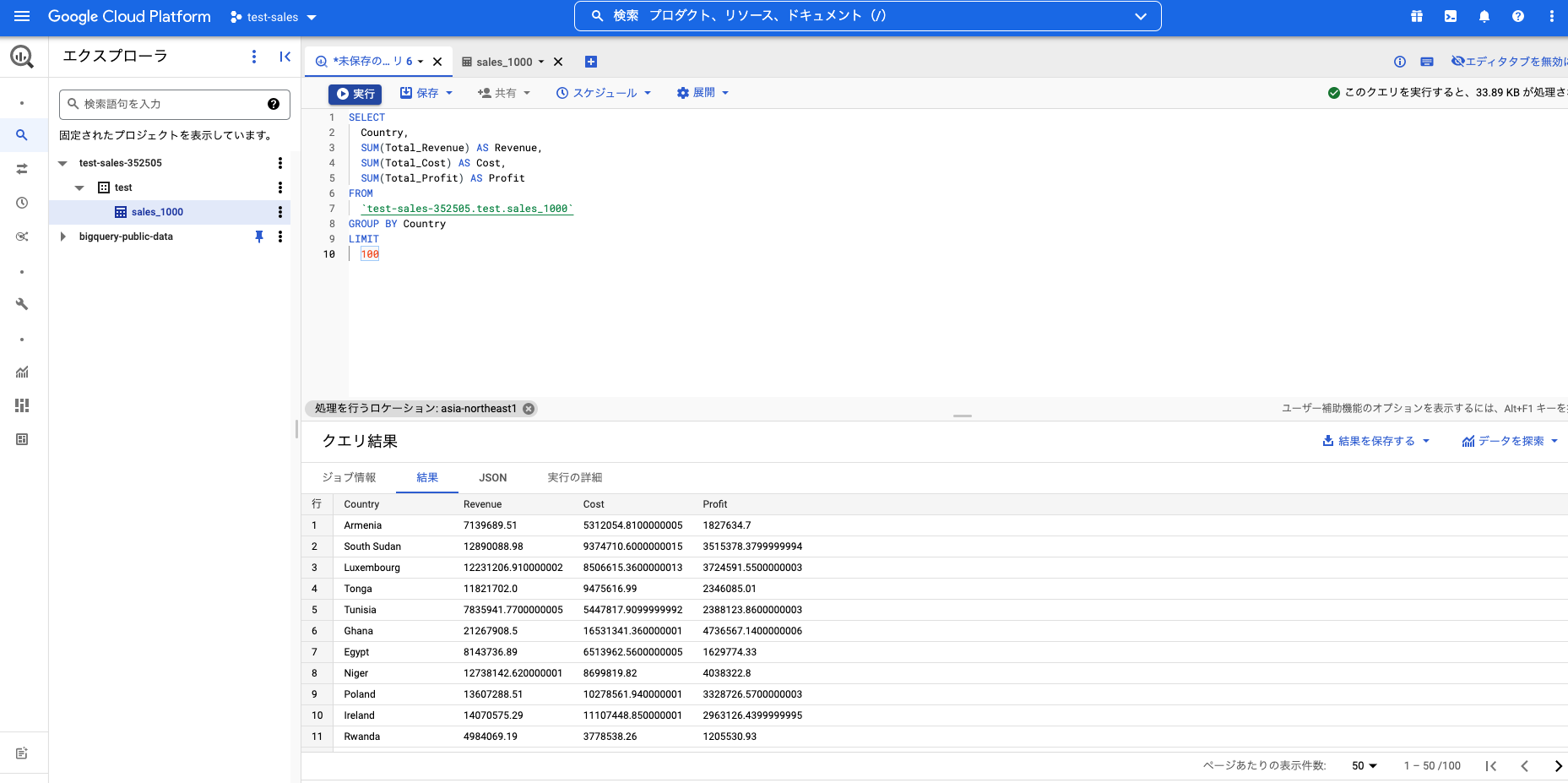
INSERTやUPDATE、DELETEなどのデータ操作言語(DML)の処理はサポートされていないようです。
「結果を保存する」をクリックして、集計結果をローカルのファイルやGoogleドライブに保存することもできます。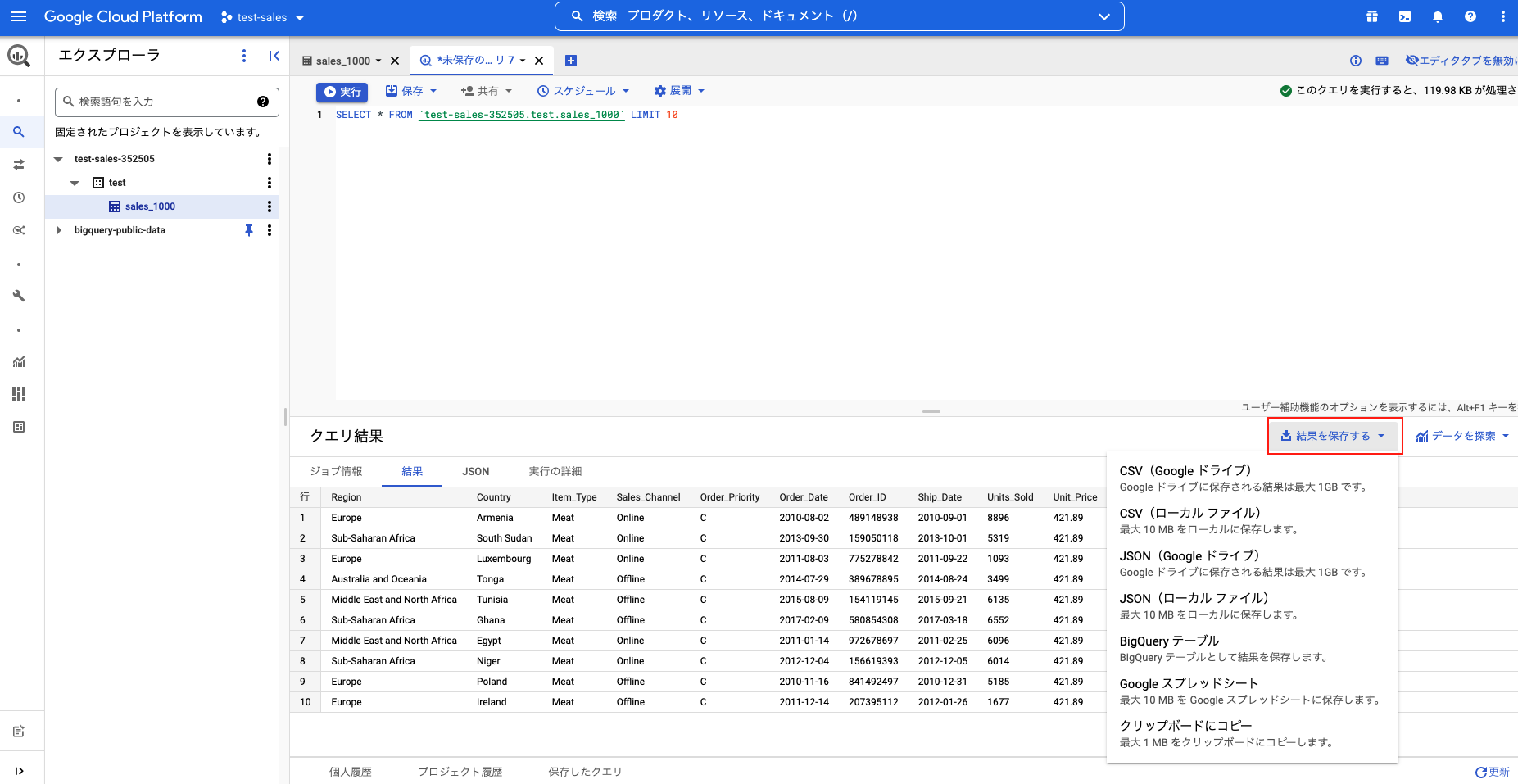
本ページでは、sandboxを利用してBigQueryの使い勝手をお試しする方法を紹介しました。
